6 min read
 David Till
David Till
Introduction
Hello SAP developers and tech enthusiasts, today I want to share my thoughts on the recent release of the Cloud Application Programming model (CAPv7), specifically on the Node.js side. In my opinion, it has quite significant changes and exciting new features we’ve been hoping for. Fancy writing less code? Yes, please. More choices of backend database? Why yes, that sounds awesome!
Before diving right in, some of you might question why? You might be thinking, my CAPv6 project is running fine, why should I bother?
The answer is quite long and varied, there are a plethora of new features that could tempt you but if that isn’t enough, security might just do it.
Security? That’s definitely relevant, given the recent uptick in large-scale cyber security-related events lately. One of the main reasons behind the CAP release schedule is to also align with the Node.js release schedule, giving its own security-related fixes, not to mention the additional features and improvements.
The diagram from this page here illustrates the schedule perfectly. For up-to-date information always refer to the official documentation.
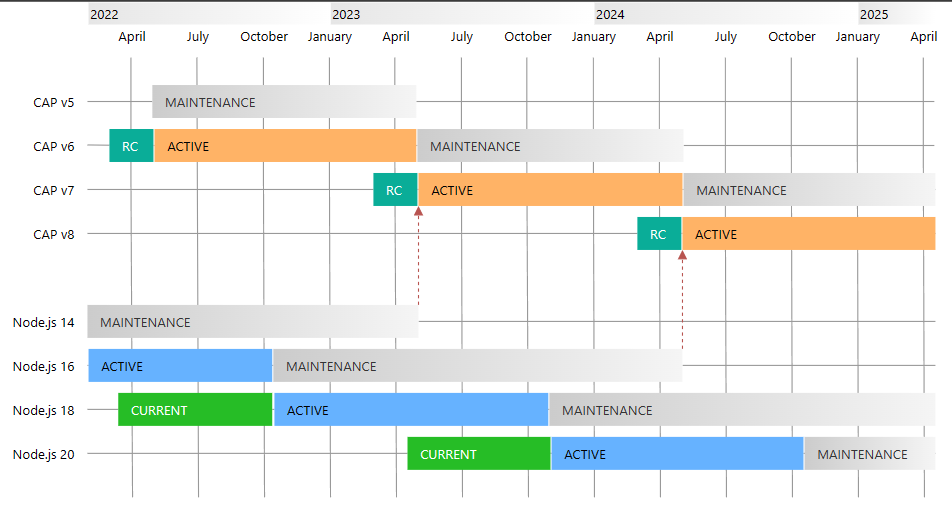
Further, the active releases will have regular feature updates, bug fixes etc whilst those versions now in maintenance will ‘only’ receive critical bug fixes as per the same page. Ultimately you will need to update when your version becomes no longer supported, so you might as well plan to do it sooner rather than later if your situation allows for it.
What now?
Having gone through an upgrade from CAPv5 to CAPv6 previously, this process was pretty much seamless. Despite the fact that our project is quite complex with 100+ tables, 8-10 separate services targeting various areas and implementing a lot of custom logic, nothing really broke.
In doing so for a CAPv6 to CAPv7 project, however, we encountered a few more of the ‘breaking’ changes and some which we didn’t even think about.
In this blog I will detail some of the key features that stood out, and some issues that came up that weren’t necessarily obvious from the start.
Plugins
Plugins can do some amazing things and help with the reusability of logic across services. Traditionally we’d been creating handlers and traditional reuse with Node.js but this way can simplify that. Further, there is one interesting plugin I’d like to dive into a bit more, GraphQL. The official Github repository is available here.
This project uses the plugin system to serve up a /graphql endpoint on your service which you can send GraphQL queries.
This project is also significant because it is one of the components that is Open Sourced, as announced in November 2022 at TechEd and detailed in the SAP Open Source review:
Why would you use GraphQL? This is a topic in itself, often, selective data is referred to as a big advantage but the same can be achieved with $select in OData. I am not sure subscriptions are currently supported so we can’t call that an advantage, I don’t believe there’s a way to mark fields as deprecated so we can’t say that either. The main reason I can think of in its current state is that it forces you to be selective about what data you need and can simplify nested queries and data that might become a bit convoluted in OData.
As always, select the technology most suited for your environment, OData obviously has clear advantages if you are building an SAP UI5 or Fiori-based application for example.
Regardless once setup in your CAP project you can do things like this:
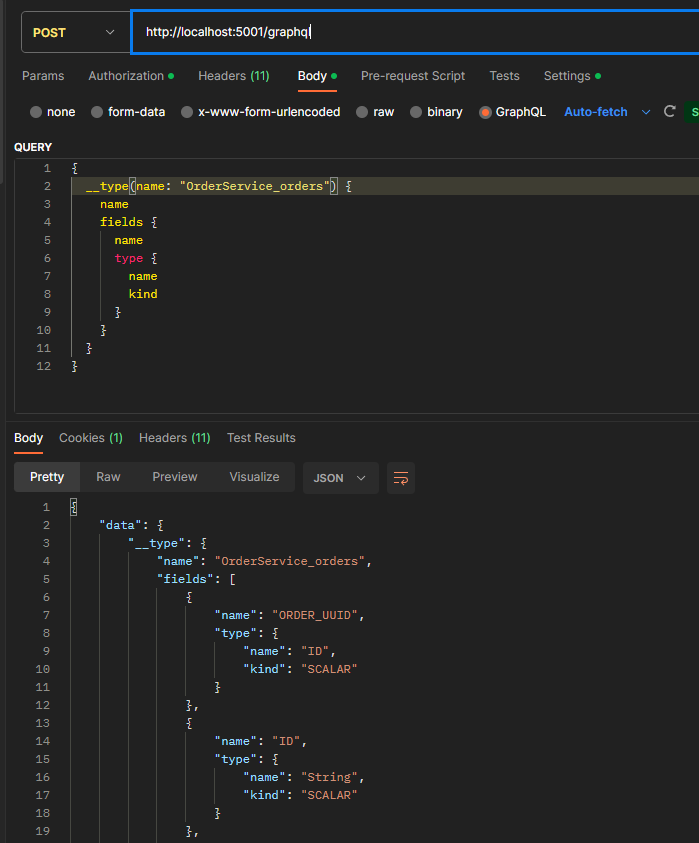
Or various introspection queries to get details about the available queries and entities:
{
__schema {
queryType {
name
}
}
}
If you are going to use this, a couple of things I noticed are that if you have entities with a Composition it seems a ‘nodes’ connection gets added in, so for example if you have Orders -> Items it adds in orders -> nodes -> items -> nodes, see below:
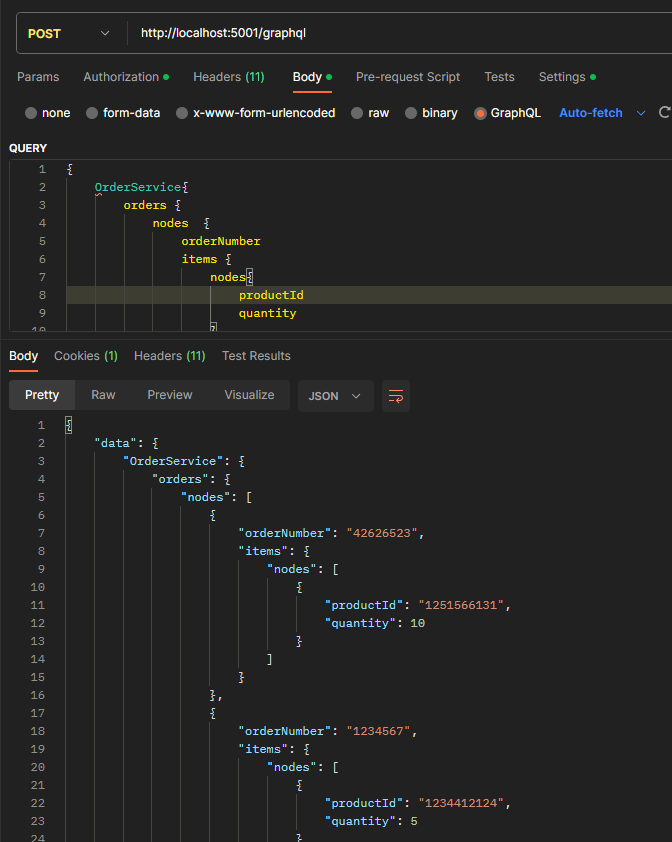
Another thing to note is that only offset-based pagination is supported currently. This is documented on the official repository. However, of course, GraphQL not specifically having any defined or required parameters, it seems they have opted for the OData style top, skip etc, so I was initially confused when ‘limit’ or ‘offset’ did not work.
To get offset-based pagination you need to use top and skip like this:
{
OrderService{
orders(top:1 skip:1) {
nodes {
orderNumber
items {
nodes{
productId
quantity
}
}
}
}
}
}
Note: This likely comes with the usual disadvantages of an offset based pagination in terms of new data being inserted or removed in between requests.
At the end of the day, it implements it how one might expect and ultimately translates to a query you may already be used to. I am looking forward to this becoming more stable and feature-rich, a proper GraphQL implementation like this could be very powerful.
Simplified Handlers
Have you ever written a handler for a read or other event and then found you have code looking like the following because if you don’t, you’ll get errors about x not being iterable?
srv.after('READ', 'orders', async(req, next) => {
await orderHandler.doSomethingComplex(orders);
});
...
doSomethingComplex = async (orders) =>{
if(!orders){ return; // No result do nothing }
if(!Array) orders = [orders];
for(let order of orders){
//do something
}
}
Now these handlers will always have an array so can be reduced to effectively the final for loop, or however, you want to process your data.
However, the caveat we had to think about, sometimes we do truly want logic to be different in the case where you have 50 results vs 1. It’s rare but we did have a few, so in this case, we had to find those and check the number of results as well, however overall it results in cleaner code.
Support for PostgreSQL
This one is huge. If you’ve followed CAP for a while you would have seen the outstanding efforts put in by a group of awesome people here.
I won’t thank everyone individually as I’m sure I’d miss someone but have a look at the contributors on this repository, simply amazing.
Now there is official support. I am, however, looking at you still, SAP – where’s the PostgreSQL console or any ability to look into the DB through the BTP Cockpit like HANA? Are we really going to have to create ssh tunnels in order to get something like this connected? (Please don’t take that feature away either)
Official support is great, with it you can build lighter prototypes or projects that don’t necessarily need a full HANA database to support it, hopefully reaching more people and bringing in new developments. I hope SAP continues to support alternative options such as this giving greater flexibility to the framework.
I have not yet used PostgreSQL apart from some tinkering, but there is also a guide to migrate from the community-driven version to the official one here.
I am looking to do a follow-up blog later on when you might want to use PostgreSQL vs HANA and possibly some performance metrics or other comparisons that might be interesting to the community.
Multiple protocols for the same definition
Ok so this one is cool if you want to serve up odata-v4 and rest for your service without creating multiple service definitions, however, if you are upgrading from v6 to v7 it is very important to note this will change your endpoints unless you have defined them explicitly already.
With a simple definition like service OrderService {…}, in v6 the path would default to /order however in v7 it will now become /odata/v4/order (assuming default of odata-v4 and no other protocol specified).
Ie
[cds] – serving OrderService { path: ‘/odata/v4/order’ }
vs
[cds] – serving OrderService { path: ‘/order’ }
One way around this is to annotate your service with the path and protocol (if needed), like so:
@protocol: ['odata-v4']
@path: '/order'
service OrderService {
...
}
However this could become messy with multiple services and also now you can’t use the multiple protocols feature with the absolute path.
Another option is to simply set the cds.features.serve_on_root to true in package.json like so:
"cds": {
"features": {
"serve_on_root": true
},
...
}
Some other things that don’t quite fit
Output from cds-serve may not reflect the protocols and paths
If you specify multiple protocols, only one will be displayed in the log, e.g. despite specifying:
@protocol: [ ‘odata-v4’, ‘rest’, ‘graphql’]
Only one is displayed here in the output, though they are all available.
[cds] – serving OrderService { path: ‘/odata/v4/order’ }
However, you’ll still get a response for requests to both /order and /odata/v4/order. It just seems like this little debug log hasn’t considered the new changes just yet but don’t despair when you can’t seem to get it to work.
If you use the feature cds.features.serve_on_root you can get the ‘wrong’ idea again from this log
For me still produces [cds] – serving OrderService { path: ‘/odata/v4/order’ }
However, /order is actually still served. Note that /odata/v4/order is also still served in this case.
So once again, don’t despair if the output doesn’t reflect what you think it should and try to connect to your service anyway.
Using cds-serve seems to be pretty much mandatory
A while back, cds-serve to start your CAP project was introduced. I believe this was due to ‘conflicts’ that may occur. I certainly encountered this when trying to use cds-swagger-ui-express, so the introduction of a different launch mechanism was welcome but just wanted to note I tried to deploy v7 without this change and it did not work for me.
Once I switched it from cds run to cds-serve, it worked fine, all you need to do is change the scripts in package.json to use cds-serve:
"scripts": {
"start": "cds-serve"
},
Fiori lean drafts
I explored the draft entities a little bit, however, we came to the conclusion it was not necessary for our scenario. One thing that did become awkward was trying to implement handlers for drafts vs active entities, but this is now simplified as you can reference the draft like MyEntity.drafts, for example, to set up a read handler:
srv.after("READ", MyEntity.drafts, () => {});
I would like to explore them a little further, however, do note if you use drafts extensively that there is a compatibility mode to reduce adoption effort, however, it will be dropped in the next version. So, start considering what you need to do to make this work.
Conclusion
This update introduces a lot of exciting features and changes, making it a significant step up from its predecessor, CAPv6. While upgrading may present some challenges, the new functionalities in this update offer benefits in terms of plugin support, simplified handlers, PostgreSQL support, and the ability to handle multiple protocols more easily.
Some of the features introduced are certainly things we could have used in the days of v6 or v5 but am delighted they are available now.
I am looking forward to diving deeper into PostgreSQL and GraphQL and whatever comes next for CAP.


